로봇의 눈을 만드는 법
가상 산업 환경을 자체 구축하고, 그 안에서 로봇의 perception AI를 훈련시킨다. NVIDIA Isaac Sim 기반 시각 데이터 수집부터 자체 학습 프레임워크까지 — 디든로보틱스가 로봇의 시각 AI를 만드는 과정.

로봇이 스스로 움직이려면 세 가지가 필요합니다. 주변 환경을 인식하는 perception, 자기 자신의 상태를 파악하는 state estimation, 그리고 실제로 다리를 움직이는 locomotion control. 디든로보틱스는 이 세 가지를 모두 자체 개발하고 있으며, 이번 시리즈에서 각 주제를 하나씩 다룰 예정입니다.
첫 번째는 perception, 로봇의 눈입니다.
눈이 없는 로봇은 한 발도 내딛지 못한다
NVIDIA Isaac Sim 화면 안에 가상의 산업 환경이 펼쳐져 있습니다. 격벽과 보강재가 반복되는 조선소 블록 구조, 그 위를 디든로보틱스의 로봇이 걸어갑니다. 실제 현장이 아닙니다. 조선소 현장의 구조적 특징을 분석해 코드로 만든 가상 환경입니다.
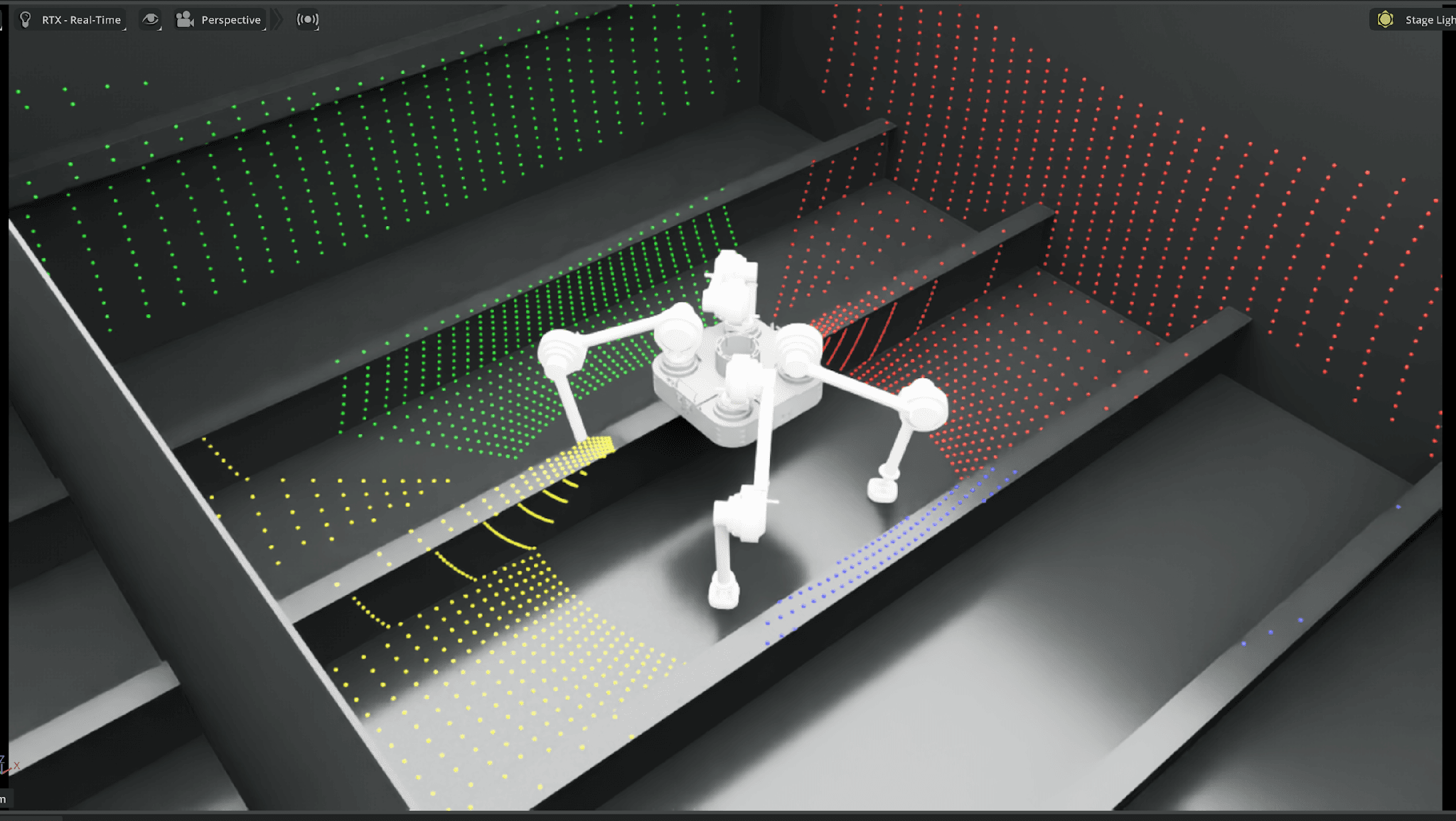
NVIDIA Isaac Sim 위의 가상 환경에서 로봇이 point cloud 데이터를 수집하는 장면
로봇이 다음 한 발을 내딛으려면, 먼저 앞에 무엇이 있는지 알아야 합니다. 장애물의 위치, 바닥의 형상, 넘어야 할 구조물의 높이. 로봇에 장착된 depth camera가 촬영한 정보를 3D 지도로 변환하는 AI가 바로 로봇의 눈입니다.

로봇에 장착된 depth camera가 포착한 화면. 밝기가 거리 정보를 나타낸다
이 AI를 훈련시키려면 방대한 학습 데이터가 필요합니다. 카메라가 촬영한 이미지와 해당 위치의 실제 3D 구조가 쌍으로, 수천에서 수만 개. 실제 산업 현장에서 이 데이터를 모으기는 어렵습니다. 생산 라인을 멈출 수 없고, 접근이 어려운 구역이 많으며, 현장마다 구조가 다릅니다.
그래서 디든로보틱스는 가상 환경에서 데이터를 만듭니다. 그리고 이 가상 환경의 중심에는 자체 개발한 시뮬레이션 파이프라인이 있습니다.
Simulation 파이프라인: Isaac Sim에서 자체 프레임워크까지
디든로보틱스의 perception 개발은 NVIDIA Isaac Sim을 시각 데이터 수집 도구로 활용하며, 자체 개발한 프레임워크에서 학습과 훈련을 수행하는 구조입니다.
가상 환경은 NVIDIA Isaac Sim 위에 구축됩니다. 디든로보틱스는 여기에 자체 설계한 로봇 모델을 불러오고, 자동 생성된 지형을 배치하고, 실제 로봇과 동일한 사양의 depth camera를 구현합니다.
Isaac Sim에서의 역할은 이 가상 환경 안에서 시각 데이터를 수집하는 것입니다. 로봇이 이동하며 depth camera로 촬영한 이미지와, 해당 위치의 3D 구조 정보가 쌍으로 기록됩니다.
수집한 데이터의 학습은 디든로보틱스가 자체 개발한 프레임워크에서 이루어집니다.
Isaac Sim에서 Visual Data를 만들고, 자체 프레임워크에서 훈련한다. 외부 플랫폼과 자체 기술을 조합한 이 구조가 디든로보틱스 perception 개발의 기반입니다.
참고로 Perception 이외의 보행, 상체 제어 등 로봇 제어는 MuJoCo Warp 시뮬레이터를 활용하여 데이터를 습득하며, 제어 학습을 위한 파이프라인 역시 자체적으로 구축하여 활용하고 있습니다.
가상 환경을 자동으로 생성한다
NVIDIA가 시뮬레이션 인프라를 제공한다면, 실제 가상 환경 구축은 디든로보틱스가 직접 진행합니다.
먼저 저희는 조선소 블록 구조의 설계 규칙을 분석하는 것에서 시작했습니다. 격벽의 간격, 보강재의 높이, access hole의 위치처럼 반복되는 패턴을 추출하고, 이를 코드로 옮겨 가상 환경을 자동 생성하는 시스템을 구축했습니다. 파라미터를 매번 다르게 설정하여, 한 번의 실행으로 수백 가지의 서로 다른 환경이 만들어집니다.

자동 생성된 가상 환경의 조감도. 격벽과 보강재가 반복되는 조선소 블록 구조가 코드로 재현되었다

같은 환경의 클로즈업. 높이와 간격이 다른 구조물들이 파라미터에 따라 자동으로 배치된다
하나의 고정된 환경이 아니라, 실제 현장에서 마주칠 수 있는 다양한 구조적 변형을 로봇에게 미리 경험시키는 것이 이 시스템의 목적입니다. 이 절차적 생성(procedural generation) 방식은 격벽과 보강재처럼 반복적이고 규칙적인 구조를 가진 산업 현장에 특히 효과적입니다. 구조의 규칙성이 높을수록 파라미터 조합만으로 다양한 변형을 만들어낼 수 있기 때문입니다.
이 가상 환경 위에서 로봇을 다양한 경로로 이동시키며 데이터를 수집합니다. 구조물 사이를 따라가는 궤적, 가로질러 이동하는 궤적, 벽면을 타는 궤적 등을 조합합니다. 세부적인 움직임에도 변동을 주어, 로봇의 다리가 카메라 시야를 가리는 상황까지 재현합니다.
보이지 않는 곳까지 추론하는 AI
이렇게 수집한 데이터로 훈련시키는 것이 Voxel Reconstruction 모델입니다.
어두운 방에서 손전등 하나를 비추는 상황을 떠올려 보면 됩니다. 빛이 닿는 곳만 보이지만, 이미 본 패턴을 기억해서 아직 비추지 않은 곳의 구조도 예측할 수 있습니다. 이 모델이 하는 일이 그것입니다. Depth camera가 포착한 부분적인 정보를 바탕으로, 보이지 않는 영역의 3D 구조까지 추론합니다.
시뮬레이션에서 이 훈련이 가능한 이유는, 가상 환경이 카메라 입력과 완벽한 3D 정답(ground truth)을 동시에 제공하기 때문입니다. 실제 환경에서는 얻기 어려운 이 정답 데이터를 대량으로 생성할 수 있다는 것이 시뮬레이션 기반 학습의 핵심 장점입니다.
디든로보틱스는 시각 모델의 성능을 높이기 위한 자체 기법도 개발했습니다. 로봇이 실제로 관측한 영역만을 학습에 반영하는 visibility masking 기법을 적용하여, 모델이 관측 가능한 영역과 불가능한 영역을 구분하도록 훈련합니다.
한 번 관측한 구조물의 정보는 메모리에 유지하여, 로봇이 이동하더라도 이전에 본 환경 정보가 사라지지 않습니다. 본 것을 기억하면서, 아직 보지 못한 것을 추론하는 것. 이것이 디든로보틱스가 perception 모델에 요구하는 능력입니다.

Voxel Reconstruction 파이프라인 전체 구조
가상에서 만들고, 현실에서 검증한다
우리가 궁극적으로 답을 찾아야 할 질문은 '시뮬레이션에서 훈련된 AI가 실제 환경에서도 작동하는가?'입니다.
가상과 현실 사이에는 아직 간극이 있습니다. 디든로보틱스가 이 간극을 줄이는 방법은 순환입니다. 실제 현장에서 로봇이 마주친 새로운 패턴이 발견되면, 가상 환경 생성 시스템에 반영합니다. 더 다양해진 환경에서 모델을 다시 훈련시키고, 개선된 모델을 다시 현장에 투입합니다. 현장의 피드백이 시뮬레이션으로 돌아가고, 시뮬레이션의 결과가 다시 현장으로 나가는 사이클입니다.
국내 조선소 현장에서 이 사이클을 반복해 온 디든로보틱스만의 경험이 시뮬레이션 환경을 점점 더 현실에 가깝게 만들어 가고 있습니다. 현재 이 perception AI가 실제 환경에서 자율 이동과 작업을 수행할 수 있도록 테스트를 준비하고 있습니다.
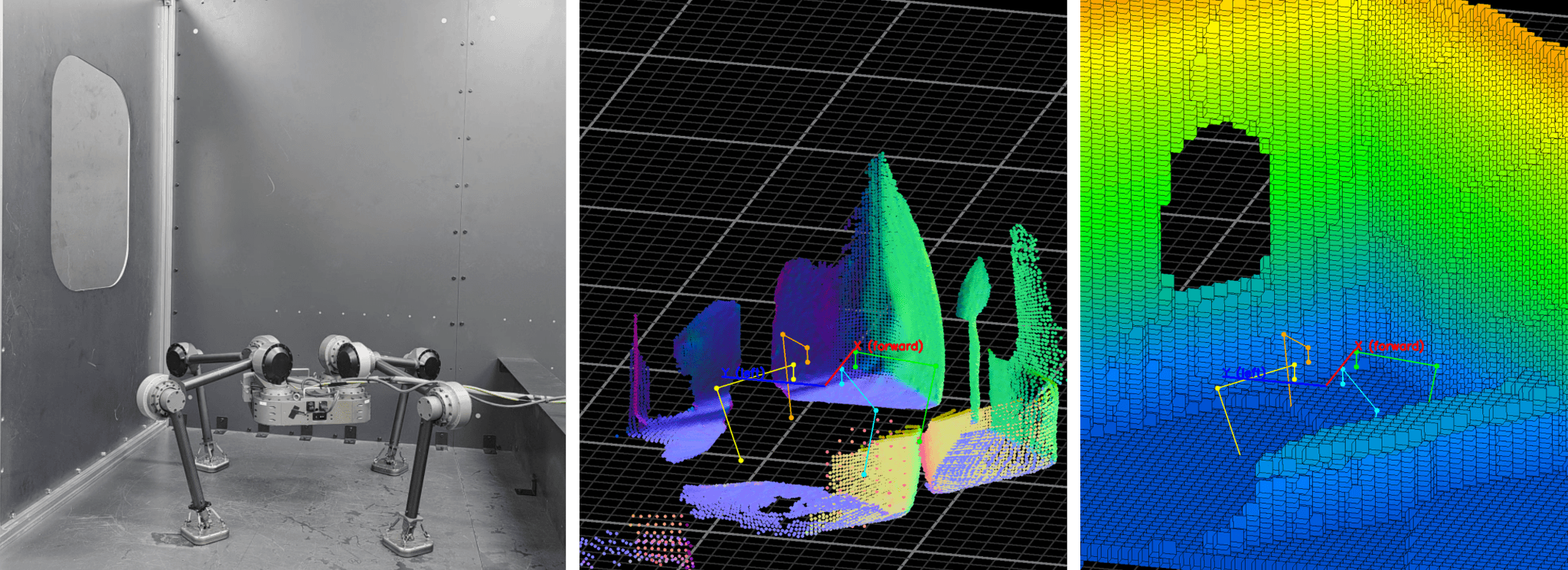
Voxel Reconstruction 모델이 복원한 로봇 주변의 3D Voxel 맵 (좌: 실제 환경, 중앙: Depth 센서 입력, 우: 모델 복원 결과)
‘눈’ 다음에 올 것들
Perception은 시작입니다. 환경을 인식한 다음에는 자기 상태를 정확히 파악해야 하고, 그 정보를 바탕으로 실제 보행을 수행해야 합니다. 이 시리즈의 다음 편에서 차례로 다룰 예정입니다.
이 perception 파이프라인은 사족보행 로봇뿐 아니라, 디든로보틱스가 개발 중인 이족보행 로봇 플랫폼에도 적용되고 있습니다. 환경 생성 시스템의 파라미터를 조정하면 다른 구조의 학습 데이터도 만들어낼 수 있습니다.
하드웨어 설계부터 시뮬레이션 환경 구축, 학습 프레임워크, perception AI 훈련까지 — 전 과정을 자체 역량으로 수행하는 것이 Physical AI 기업 디든로보틱스가 로봇의 눈을 만드는 방법입니다.