How a Robot Learns to Move with Reinforcement Learning
For a robot, moving through an industrial site is more than walking — it is the bundled problem of crossing rough surfaces, stepping over stiffeners, and threading through narrow passages. DIDEN Robotics is developing a quadrupedal robot and a bipedal platform together on the same learning framework and the same in-house hardware, combining model-based and learning-based control to solve the complex terrain of industrial sites. This is the locomotion pipeline from DIDEN Robotics, the Physical AI company built for industrial environments.

The interior of a ship is filled, end to end, with ladders, narrow passageways, and waist-high stiffeners running between bulkheads. For a robot to do any actual work in a place like this, one capability has to come first: the ability to traverse all of that terrain on its own and reach the next work point. Locomotion.
This is the third installment in our series. Part 1, Building a Robot’s Eyes, covered Perception. Part 2, How a Robot Finds Itself, covered State Estimation. This installment covers the layer that finally lets the robot move on top of those two foundations: Locomotion.
What It Means to Move Through an Industrial Site
Locomotion is often heard as just walking, but in industrial environments it covers a much wider concept:
walking on flat ground
crossing rough surfaces littered with debris without slipping
stepping over waist-high stiffeners
threading through passageways barely wide enough for a human
In an industrial site, all of these belong to the same single problem. Standing stably in one place and reaching the next work point through complex terrain are both required before the robot can do any actual work.
Industrial environments are demanding for a reason. A ship, a construction site — these spaces are designed for human bodies. To use facilities built for people while also performing real work, a robot has to deliver two things at once: stability that does not collapse in any posture, and traversal capability close to a human’s stride.
That is why DIDEN Robotics develops a quadrupedal robot and a bipedal platform side by side. The quadruped uses magnetic feet to move freely between floors and walls and to hold its working posture, while the biped moves through infrastructure built for people. Different forms, but the same destination — industrial sites — and the same kind of problems to solve.
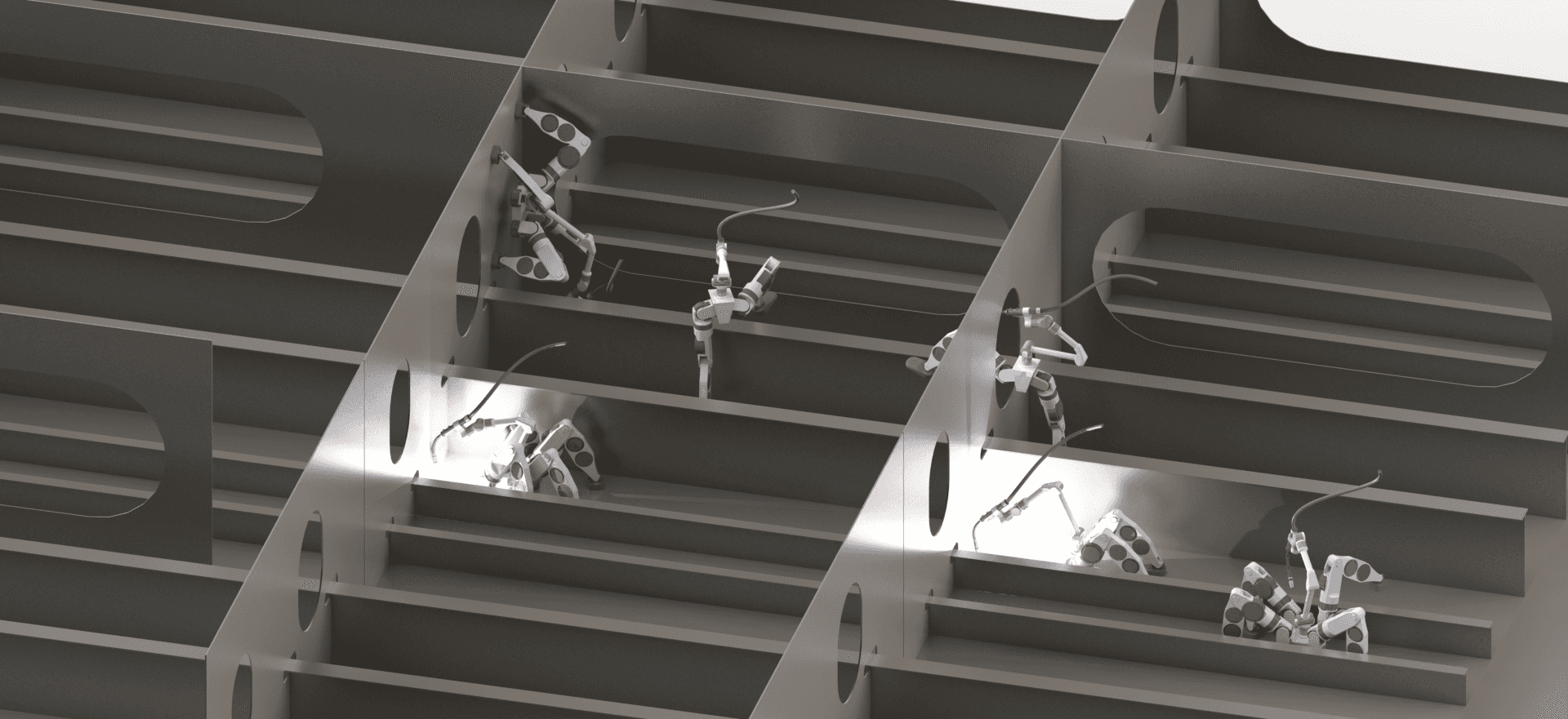
A concept rendering of quadrupedal and bipedal robots operating inside an industrial environment of repeating bulkheads, stiffeners, and access holes.
Three Problems Learning-Based Locomotion Has to Solve
When bringing learning-based Locomotion into industrial environments, DIDEN Robotics identifies three core problems.
Problem 1 — The robot doesn’t know what “moving well” looks like.
A person can be told to “walk lightly” or “walk steadily” and understand. A robot needs that translated into a mathematical reward. Is it tracking the commanded velocity? Is it lifting its foot in step with the gait period? Is the foot trajectory consistent? Is it slipping? Encoding human intuition into a mathematical scoring system is itself the first hurdle.
Problem 2 — There is a gap between simulation and reality.
Training takes place inside fast simulation, but the robot has to operate in the physical world. Friction coefficients, motor backlash, magnetic-foot adhesion forces, mechanical sag — all assumed in simulation. Even small mismatches between those assumptions and reality can turn a robot that moves well in simulation into one that wobbles in the field. When DIDEN Robotics talks about the sim-to-real problem, this is the control-transfer gap it means.
Problem 3 — Data is scarce.
Walking on flat ground can be learned by simply iterating long enough, but high-difficulty motions like stepping over stiffeners and passing through access holes rarely succeed from a cold start. Collecting data with high reward signals is hard, and even when collected, getting to a useful training volume takes time.
DIDEN Robotics’ Solutions: Models and Learning Together, Quadruped and Biped Together
DIDEN Robotics tackles these three problems together by building a pipeline that combines model-based and learning-based control. And that pipeline runs across both quadrupedal and bipedal forms at the same time.
Solution 1 — Translating human intuition into rewards
The starting point for reinforcement learning is straightforward. Rather than handing the robot a list of rules, the team defines what to reward and what to penalize. An actor that decides actions and a critic that evaluates their value are trained together, and the policy is gradually refined as a result. DIDEN Robotics adds two more devices on top of that:
Adaptive Gait Period — keeps the stride length consistent even when the commanded velocity changes.
Curriculum Learning — steps the policy through low-difficulty terrain before exposing it to the hardest.
(The same idea by which a person learns a sport: starting from the basics and gradually raising the difficulty.)

Adaptive Gait Period (left) and Curriculum Learning (right) running on the quadrupedal robot inside simulation.
Solution 2 — Closing the sim-to-real gap with direct measurement
The second solution starts from the fact that DIDEN Robotics designs its own hardware. With externally sourced parts, you depend on whatever theoretical values appear in the spec sheet. With in-house actuators and magnetic feet, every parameter can be measured directly.
DIDEN Robotics measures how much backlash a motor actually has, how adhesion changes between current-on and current-off states, and what the friction coefficient of a steel surface really is — and folds those measurements back into the simulation environment. A policy trained on a simulator calibrated against real measurements moves the same way on the real robot as it moves in simulation.
Solution 3 — A two-stage approach: imitate the demonstration, then surpass it
The third problem is solved not by collecting new data, but by using the data already on hand in two distinct stages.
First, motion-tracking reinforcement learning lays down the basics. DIDEN Robotics already has high-difficulty motion data captured through model-based control algorithms or teleoperation. The team extracts joint positions and velocities from this data and uses them as the input to training. At this stage, the captured data provides the joint angles and positions (kinematics) the robot should take, and motion-tracking learning realizes that as actual motion. It is, in human terms, the stage of watching an expert’s demonstration and learning the trajectory of each movement.
Next, off-policy reinforcement learning layers on top. Rather than stopping at imitation, this stage searches for the optimal motion that maximizes physical efficiency. Here, the torque data derived from model-based control is converted to an equivalent action representation and used as training material. Off-policy can use past experience, data generated by entirely different algorithms, and even failure data — which gives it dramatically higher data efficiency than motion-tracking RL alone.
Combining the two stages this way solves the data-scarcity problem and, at the same time, overcomes the training-stability challenges that come up when off-policy learning is brought onto real robots — letting the quadrupedal robot’s on-robot training converge successfully.

Inside the simulation, the bipedal platform learns a range of motions on the same learning framework as the quadrupedal robot.
Robust walking across terrain
What sets DIDEN Robotics’ walking apart from other robots, at this point in the pipeline, is robustness across terrain. The trained policy operates stably not on the flat ground of a simulator, but on rough surfaces littered with welding debris and on complex terrain of repeating stiffeners.
Both the quadruped and the biped are built on the same in-house actuator modules designed and produced by DIDEN Robotics. The two robots share the same hardware foundation and pass through the same learning pipeline — motion-tracking RL followed by off-policy RL — as they evolve.
Evolving in the Same Rhythm
This pipeline did not appear in one piece. It is the result of stacking one capability on top of another, step by step.
In the beginning, it ran only inside simulation — access-hole traversal with the robot unloaded was the starting point.
Next, learning-based walking moved out into real environments. The quadrupedal robot held its footing on floors covered in welding spatter — the metallic debris generated during welding. A new training method was introduced for the quadruped: difficult-motion data generated by model-based control was used as a target for the learned policy to track. In the same flow, the bipedal platform achieved humanoid-form walking compatible with human-centric infrastructure.

A simulation showing the quadrupedal robot walking stably on a rough surface scattered with welding spatter (the metallic debris from welding.
Most recently, the in-house actuator advanced one generation further. The new actuator and new motor boards were applied to both platforms in parallel. Motion-tracking reinforcement learning moved beyond simulation and onto the real quadrupedal robot — when external forces are applied or the starting position shifts, the trained policy keeps tracking the reference motion robustly.
The bipedal platform, in just three months, reached the point of working in-house hardware and working walking control on top of it — with bipedal walking running stably on the new-generation hardware. Access-hole capability advanced as well, with traversal extending to tighter passages.

The bipedal platform balancing on two feet and walking with the new motor boards.
The flow, summarized:
Develop the same in-house actuator for quadruped and biped
→ fold the actual hardware specs into simulation and learn walking
→ run walking tests on the same hardware in the real environment
→ collect real-world data and recycle it back into training.
In-house hardware and an in-house training framework moving in lockstep is what allowed the two platforms’ locomotion to advance together.
What Comes Next: Out of Simulation
The next step’s center of gravity moves out of simulation.
A walking test inside a real ship environment is scheduled in the near future. It is the stage of checking how the trained policy behaves on an actual vessel rather than on a flat lab platform. In the same flow, the bipedal platform is set to integrate its lower and upper body into a full-body form, and the training pipeline expands toward solving access-hole traversal through reinforcement learning.
DIDEN Robotics is taking another step beyond a single-policy controller by separating walking into two layered policies for more intelligent motion:
High-level policy — uses Perception information to reason about which foot to move where and how, generating the motion.
Low-level policy — controls the robot to track the motion generated by the high-level policy stably.
Once the two layers are separated, the same hardware can produce walking that is more refined and more intelligent.
Beyond the maritime market, other industrial environments wait — manufacturing, logistics, facility management — all spaces where robots have to follow the same routes and use the same fixtures as people. The fact that DIDEN Robotics is advancing quadruped and biped in the same rhythm is what determines the breadth of industries the company’s robots can reach.
After Perception gave the robot its eyes and State Estimation gave it a sense of place, Locomotion is what stops the robot from staying still. Building the entire stack in-house — hardware design, environmental recognition, self-localization, and locomotion control across both quadrupedal and bipedal forms — is what defines DIDEN Robotics as a Physical AI company built for industrial environments.
South Korea
©Copyright DIDEN Robotics. All Right Reserved
Terms of Service
|
Privacy Policy
|
Legal Notice
|
Prohibition of Unauthorized Email Collection
Diden Robotics Co., Ltd.
|
Representative: Junny(Joon-Ha) Kim
|
Contact: diden@didenrobotics.com / Phone: 02-6959-0642 / Fax: 02-6959-0643
|
49 Achasan-ro 17-gil, Seongdong-gu, Seoul, Rooms 401, 402, 409, 410 (04799)
|
Business Registration Number: 867-87-03056
DIDEN ROBOTICS